Cineromycin B¶
Summary:
In our previous work (DOI: 10.1002/jcc.23738), we determine solution-state conformational populations of the 14-membered macrocycle cineromycin B (O-desmethyl albocycline), using a combination of previously published sparse Nuclear Magnetic Resonance (NMR) observables and replica exchange molecular dynamic/Quantum mechanics (QM)-refined conformational ensembles. Cineromycin B is a 14-membered macrolide antibiotic that has become increasingly known for having activity against
methicillin-resistant Staphylococcus Aureus (MRSA). In this example, we show how to calculate the consistency of computational modeling with experiment, and the relative importance of reference potentials and other model parameters. We will walk through the process of setting up a biceps script. You are welcome to take this as a template for you and make necessary modification to get it work for you. All input files used in this tutorial are prepared from this tutorial.
To convert this Jupyter Notebook into a script use the following command:
$ jupyter nbconvert --to python cineromycinB.ipynb
First, we need to import source code for BICePs classes. More information of these classes can be found here.
[1]:
import numpy as np
import pandas as pd
import biceps
BICePs - Bayesian Inference of Conformational Populations, Version 2.0
[2]:
# What possible experimental data does biceps accept?
print(f"Possible data restraints: {biceps.toolbox.list_possible_restraints()}")
print(f"Possible input data extensions: {biceps.toolbox.list_possible_extensions()}")
Possible data restraints: ['Restraint_cs', 'Restraint_J', 'Restraint_noe', 'Restraint_pf']
Possible input data extensions: ['H', 'Ca', 'N', 'J', 'noe', 'pf']
Now we need to specify input files and output files folder.
[3]:
####### Data and Output Directories #######
energies = np.loadtxt('cineromycin_B/cineromycinB_QMenergies.dat')*627.509 # convert from hartrees to kcal/mol
energies = energies/0.5959 # convert to reduced free energies F = f/kT
energies -= energies.min() # set ground state to zero, just in case
# REQUIRED: specify directory of input data (BICePs readable format)
input_data = biceps.toolbox.sort_data('cineromycin_B/J_NOE')
# REQUIRED: specify outcome directory of BICePs sampling
outdir = 'results'
# Make a new directory if we have to
biceps.toolbox.mkdir(outdir)
Next, we need to specify number of steps for BICePs sampling. We recommend to run at least 1M steps for converged Monte Carlo samplings. In BICePs, we also prepare functions of checking convergence of Monte Carlo. More information can be found here.
[4]:
# REQUIRED: number of MCMC steps for each lambda
nsteps = 100000 # 100 k steps for testing
#nsteps = 10000000 # 10 M steps for production
We need to specify what lambda values we want to use in BICePs samplings. Briefly, lambda values are similar to the parameters used in free energy perturbation (FEP) and has effect on the BICePs score. The lambda values represent how much prior information from computational modeling is included in BICePs sampling (1.0 means all, 0.0 means none). As we explained in this work, one can consider BICePs score as the relative free energy change between different models. More lambda values will increase the samplings for multistate Bennett acceptance ratio (MBAR) predictions in free energy change and populations. However more lambda values also will slow down the whole process of BICePs (as more samplings need to run), so balancing the accuracy and efficiency is important. To successfully finish a BICePs sampling, lambda values of 0.0 and 1.0 are necessary. Based on our experience, the lambda values of 0.0,0.5,1.0 are good enough for BICePs sampling.
[5]:
# REQUIRED: specify how many lambdas to sample (more lambdas will provide higher
# accuracy but slower the whole process, lambda=0.0 and 1.0 are necessary)
n_lambdas = 2
lambda_values = np.linspace(0.0, 1.0, n_lambdas)
print(lambda_values)
[0. 1.]
Print what experimental observables are included in BICePs sampling. This is optional and provides a chance for double check before running BICePs sampling.
In this tutorial, we used both J couplings and NOE (pairwise distances) in BICePs sampling.
[6]:
# OPTIONAL but RECOMMENDED: print experimental restraints included (a chance for double check)
print(f"Input data: {biceps.toolbox.list_extensions(input_data)}")
Input data: ['J', 'noe']
Another key parameter for BICePs set-up is the type of reference potential for each experimental observables. More information of reference potential can be found here.
Three reference potentials are supported in BICePs: uniform (‘uniform’), exponential (‘exp’), Gaussian (‘gau’).
As we found in previous research, exponential reference potential is useful in most cases. Some higher level task may require more in reference potential selection (e.g force field parametrization).
(Note: It will be helpful to print out what is the order of experimental observables included in BICePs sampling as shown above.)
Users can specify reference potential to use for each experimental observable will be in the same order as input_data. If you want, you can specify nuisance parameters (uncertainty in experiments) range but it’s not required. Our default parameters range is broad enough. “gamma” is a scaling factor converting distances to NOE intensity in experiments. It is only used when NOE restraint is used in BICePs sampling.
[7]:
parameters = [
{"ref": 'uniform', "sigma": (0.05, 20.0, 1.02)},
{"ref": 'exp', "sigma": (0.05, 5.0, 1.02), "gamma": (0.2, 5.0, 1.02)}
]
pd.DataFrame(parameters)
[7]:
| ref | sigma | gamma | |
|---|---|---|---|
| 0 | uniform | (0.05, 20.0, 1.02) | NaN |
| 1 | exp | (0.05, 5.0, 1.02) | (0.2, 5.0, 1.02) |
Now we need to set up BICePs samplings and feed arguments using variables we defined above. In most cases, you don’t need to modify this part as long as you defined all these parameters shown above.
[8]:
####### MCMC Simulations #######
for lam in lambda_values:
print(f"lambda: {lam}")
ensemble = biceps.Ensemble(lam, energies)
ensemble.initialize_restraints(input_data, parameters)
sampler = biceps.PosteriorSampler(ensemble)
sampler.sample(nsteps=nsteps, print_freq=10000, verbose=True)
sampler.traj.process_results(f"{outdir}/traj_lambda{lam}.npz")
lambda: 0.0
Step State Para Indices Avg Energy Acceptance (%)
0 [33] [152, 116, 81] 115.986 100.00 True
10000 [87] [216, 132, 100] 5.062 65.87 True
20000 [87] [207, 142, 101] 5.995 65.39 False
30000 [87] [217, 151, 96] 6.373 66.44 False
40000 [27] [250, 155, 101] 8.502 68.63 True
50000 [52] [248, 152, 97] 9.648 70.16 False
60000 [80] [244, 146, 100] 10.014 71.43 True
70000 [87] [206, 126, 96] 6.370 70.97 True
80000 [27] [250, 129, 101] 6.577 71.13 True
90000 [67] [270, 139, 96] 8.676 71.48 False
Accepted 71.757 %
Accepted [ ...Nuisance paramters..., state] %
Accepted [32.522 30.326 30.326 8.909] %
lambda: 1.0
Step State Para Indices Avg Energy Acceptance (%)
0 [66] [152, 116, 81] 130.699 100.00 True
10000 [85] [256, 152, 100] 8.310 63.53 True
20000 [85] [247, 142, 96] 7.232 64.17 True
30000 [80] [263, 135, 101] 7.358 64.18 True
40000 [80] [273, 141, 98] 7.216 64.37 False
50000 [59] [269, 127, 95] 6.117 64.34 True
60000 [59] [230, 120, 98] 6.436 64.30 False
70000 [38] [259, 157, 87] 8.732 64.21 True
80000 [38] [247, 134, 94] 5.074 64.26 False
90000 [59] [246, 139, 95] 5.567 64.32 True
Accepted 64.378 %
Accepted [ ...Nuisance paramters..., state] %
Accepted [32.574 30.181 30.181 1.623] %
Note that all output trajectories and images will be placed in the previously defined ``outdir`` as ‘results_ref_normal’…
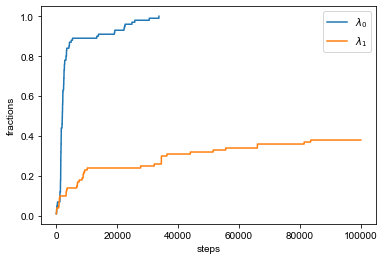
Also note that the user can quickly check to see if our MCMC trajectories have converged using our ``biceps.convergence`` module. See `this tutorial <https://biceps.readthedocs.io/en/latest/examples/Tutorials/Convergence/convergence.html>`__ for an example and more details.
Then, we need to run functions in Analysis to get predicted populations of each conformational states and BICePs score. A figure of posterior distribution of populations and nuisance parameters will be plotted as well.
The output files include: population information (“populations.dat”), figure of sampled parameters distribution (“BICePs.pdf”), BICePs score information (“BS.dat”).
[9]:
############ MBAR and Figures ###########
%matplotlib inline
# Let's do analysis using MBAR algorithm and plot figures
A = biceps.Analysis(trajs=f"{outdir}/traj*.npz", nstates=len(energies))
A.plot(show=True)
Loading results/traj_lambda0.0.npz ...
Loading results/traj_lambda1.0.npz ...
not all state sampled, these states [ 0 1 4 5 7 8 9 11 12 13 15 16 18 20 21 22 23 24 25 26 27 28 29 31
33 34 36 40 42 43 44 48 51 52 53 54 55 57 60 61 62 63 64 69 71 73 74 75
76 77 78 81 83 86 87 88 89 95 96 97 98 99] are not sampled
Loading results/traj_lambda0.0.pkl ...
Loading results/traj_lambda1.0.pkl ...
lam = [0.0, 1.0]
nstates 100
Writing results/BS.dat...
Writing results/populations.dat...
Top 10 states: [46, 92, 45, 85, 39, 65, 80, 90, 59, 38]
Top 10 populations: [0.0162745 0.02517608 0.02937356 0.05370308 0.06233372 0.09602128
0.10226967 0.10690115 0.19453062 0.28411628]
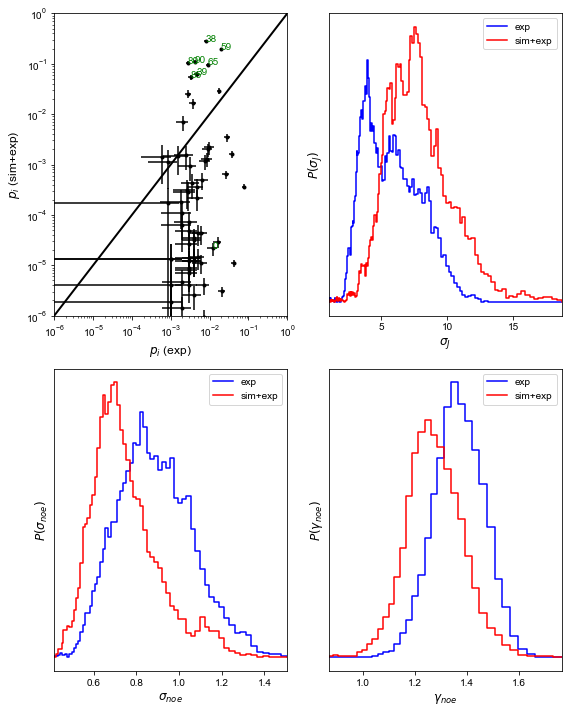
Now, let’s take a look at the output figure above (“BICePs.pdf”).
The top left panel shows the population of each states in the presence (y-axis) and absense (x-axis) of computational modeling prior information. You can find some states (e.g state 38, 59) get awarded after including computational prior information. If you check this work you will see how misleading the results will be if we only use experimental restraints without computational prior information. The other three panels show the distribution of nuisance parameters in the presence or absence of computational modeling information. It may not be clear in this example due to the limit of finite sampling, but based on our experience, including prior information from our simulations will lower the nuisance parameters than only using experimental restraints.
Next, let’s take a look at the populations file.
There are 100 rows corresponding to 100 clustered states. Four columns corresponding to populations of each state (row) for 2 lambda values (first 2 columns) and population change (last 2 columns).
[10]:
import pandas as pd
pops = np.loadtxt(outdir+'/populations.dat')
df = pd.DataFrame(pops)
print(df)
0 1 2 3
0 0.011978 2.162798e-05 0.003435 6.277576e-06
1 0.003988 1.191602e-05 0.001990 5.968855e-06
2 0.008710 1.290053e-03 0.002743 4.092921e-04
3 0.000987 1.306724e-05 0.000986 1.307306e-05
4 0.000000 0.000000e+00 NaN NaN
.. ... ... ... ...
95 0.016000 4.324363e-11 0.003965 NaN
96 0.003964 3.553772e-05 0.001978 1.780078e-05
97 0.003988 1.196024e-05 0.001990 5.991005e-06
98 0.004000 5.817569e-11 0.001996 NaN
99 0.001000 2.578042e-07 0.000999 2.579209e-07
[100 rows x 4 columns]
# NOTE: The following cell is for pretty notebook rendering
[11]:
from IPython.core.display import HTML
def css_styling():
styles = open("../../../theme.css", "r").read()
return HTML(styles)
css_styling()
[11]: